
Protiva Rahman
Assistant Professor, Health Outcomes & Biomedical Informatics · University of Florida
Faculty Liaison and NLP Co-lead · OneFlorida+
I am interested in building tools to democratize data science in the domains of infectious diseases and cancer. My research spans the disciplines of data science, natural language processing, and human-computer interaction. My overarching goal is to bridge the gap between data science and domain experts. To this end, my PhD thesis presented a framework to amplify expertise in clinical data pipelines while my postdoctoral work aimed to automate data extraction from unstructured texts such as EHR notes and biomedical literature. I received my PhD in Computer Science from The Ohio State University in August 2020 and completed my postdoctoral training at the Vanderbilt University Medical Center. My ongoing projects include immune checkpoint inhibitor (ICI) related adverse events, maternal opioid usage, and OneFlorida+ data quality.
News
- May 2026: Excited to receive a CTSI Pilot Award to study ICI related endocrinopathies
- March 2026: Congratulations to Asha on getting accepted to Harvard's Data Science Program! Asha made great contributions as an undergraduate research assistant in our lab
- 2025: Congratulations to Jeremy Balch on successfully defending his PhD and publishing our work at JMIR
- 2024: New JCO manuscript on predicting toxicities of immune checkpoint inhibitors(ICI)
- June 2023: Excited to join University of Florida as a Research Assistant Professor in Biomedical Informatics!
- March 2023: New JAMIA paper on automating immunocheckpoint inhibitor induced colitis from the EHR!
- Nov 2022: Presenting a poster and paper at AMIA on automated data extraction from biomedical literature!
- Oct 2022: I am on the academic job market! Please reach out if you have openings in Biomedical Informatics or Computer Science.
- June 2022: Submitted my first K99/R00 grant to NCI!
- Nov 2021: Megan and Rachel are presenting our work on the novel PRESCIANT method at AHA[paper]
- Oct 2021: Excited to attend AMIA in person after two years and present our work on Automating Data Curation from Unstructured Text[pdf]
- July 2021: Our ASCO poster was highlighted in Oncology Nurse Advisor
- June 2021: Presenting our work on Predicting Brain Mets in NSCLC patients at ASCO 2021
- Nov 2020: Virtually presenting a podium abstract on my thesis work at AMIA
- Sept 2020: Moved to Nashville and started my postdoc at Vanderbilt University Medical Center
- Aug 2020: I successfully defended my Ph.D. thesis!
- July 2020: Our framework for Amplifying Domain Expertise was accepted to JMIR Medical Infomatics
- Jan 2020: Our review paper on Evaluating Interactive Data Systems was published in the VLDB Journal
- April 2019: Excited to be interning with NIH/NLM/NCBI Pubmed Labs this summer
- Dec 2018: Transformer was accepted to IUI 2019
- Aug 2018: Presenting our work on visualizing rules at DSIA on October 21st
- July 2018: Icarus got accepted to VLDB 2018, see you in Rio
- May 2018: Presenting our tutorial on Evaluating Interactive Data Systems at SIGMOD on June 12th
- April 2018: Participating at the Ph.D. Consortium at IEEE ICHI in May
Selected Publications
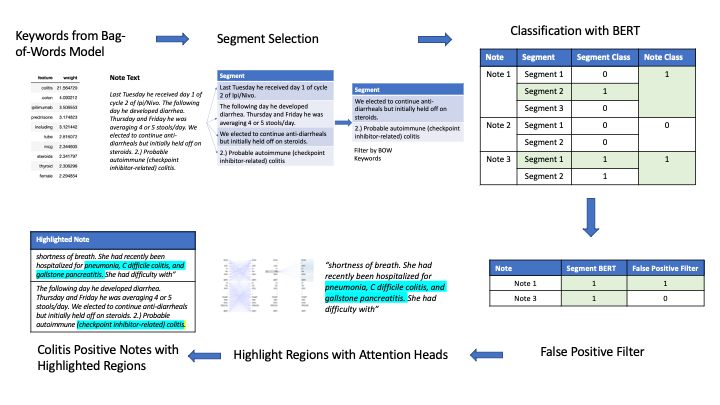
Automated Curation of Checkpoint Inhibitor Side-Effects from EHR
Protiva Rahman, Cheng Ye, Kathleen Mittendorf, Michele LeNoue-Newton, Christine Micheel, Jan Wolber, Travis Osterman, Daniel Fabbri. JAMIA 2023. [pdf][poster]
While checkpoint inhibitors (CPI) have improved cancer treatment, they cause side-effects such as CPI-induced colitis which reduce patient's quality of life. Predictive models for CPI-induced colitis can allow physicians to adapt their care. However, these models require data extracted from the EHR since CPI-induced colitis do not have clear diagnosis codes and keyword search returns over 200,000 notes with a 10% accuracy. In this work we present data pipelines which extract EHR notes related to CPI-induced colitis with 84% precision and reduced note review load by 75%.
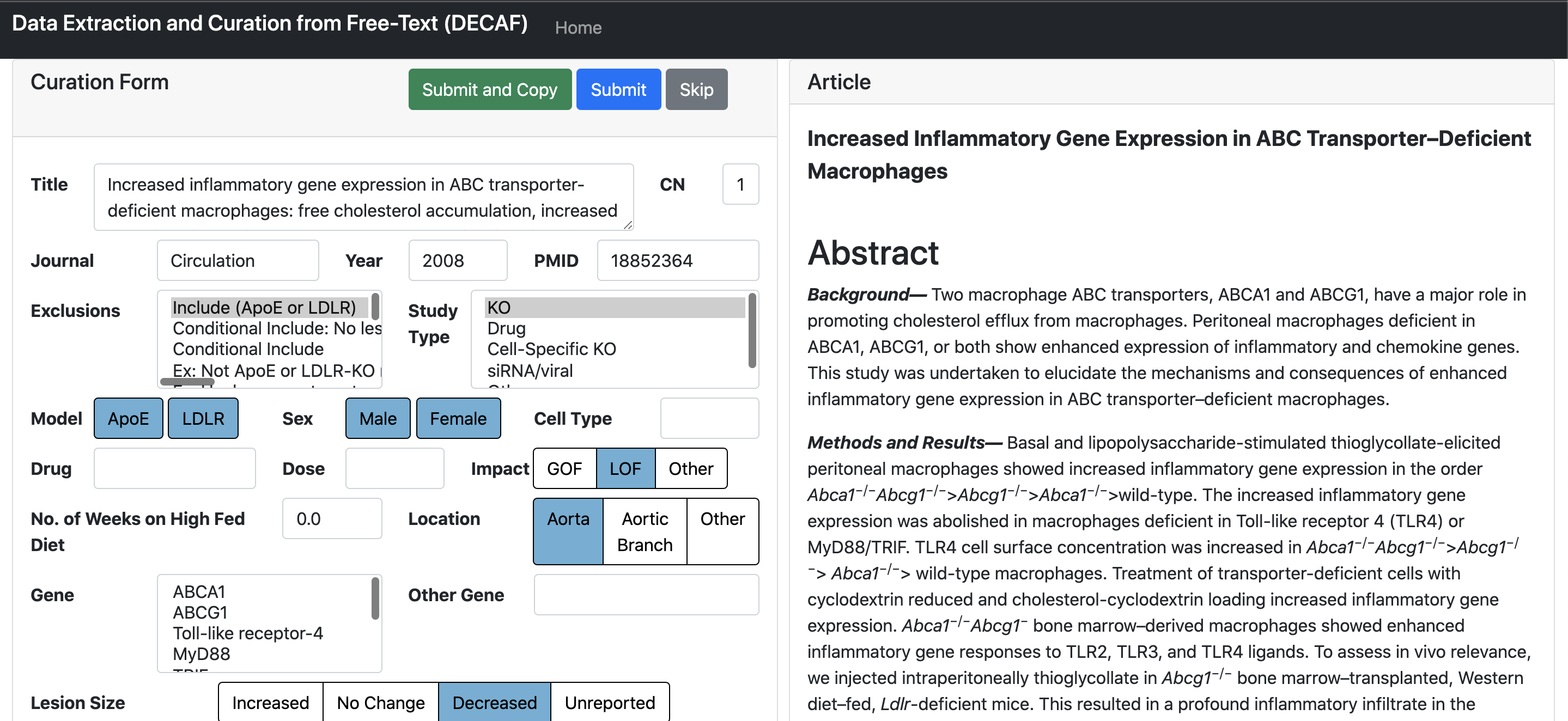
Semi-Automated Data Curation from Biomedical Literature
Protiva Rahman, Rachel Xiang, Yihua Wang, Joshua Beckman, Quinn Wells, Iris Jaffe, Megan Shuey, Daniel Fabbri. AMIA 2022. [pdf]
Aggregating data from preclinical studies to identify and validate novel pathways in humans using the PRESCIANT method [paper] requires data extraction from biomedical literature. In this work, we present a preliminary tool which uses NLP methods to automatically extract and populate a web form which can be reviewed by curators. Our NLP model has a 70% accuracy on categorical fields and our curation tool accelerates task completion time by 49% compared to manual curation.
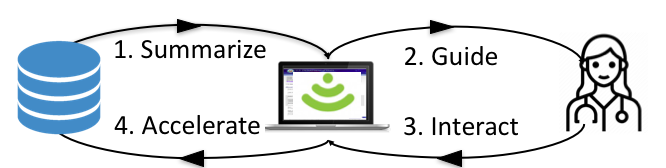
Amplifying Domain Expertise in Clinical Data Pipelines
Protiva Rahman, Arnab Nandi, Courtney Hebert. JMIR Medical Informatics 2020. [pdf]
Domain expertise is needed at all stages of the data pipeline from collection to cleaning and not just at the analysis stage. While tools exist to incorporate domain expert feedback to a limited stage for the analysis stage, tools at earlier pipeline steps focus on data scientist and neglect domain experts who have different needs and skills. We present a framework to amplify domain expertise through the entire data pipeline. This involves building systems that summarize data, guide the user, allow interactive updates, and accelerate domain expert's task. Expertise amplification is demonstrated with a case study.
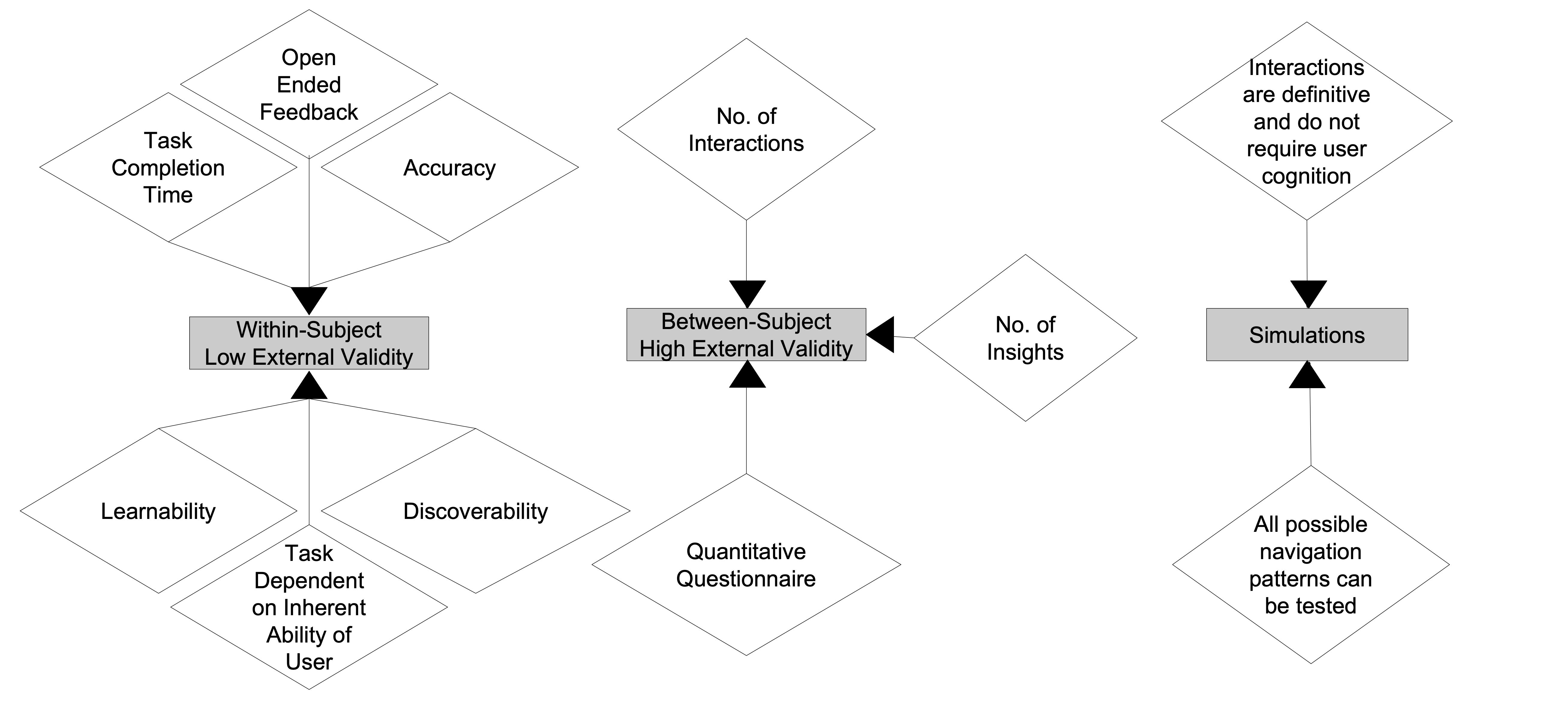
Evaluating Interactive Data Systems
Protiva Rahman, Lilong Jiang, Arnab Nandi. VLDB Journal 2020. [pdf][tutorial slides][github]
We extensively survey the literature to guide the development and evaluation of interactive data systems. We highlight unique characteristics of interactive workloads, discuss confounding factors when conducting user studies, and catalog popular metrics for evaluation. We further delineate certain behaviors not captured by these metrics and propose complementary ones to provide a complete picture of interactivity. Our survey and case studies motivate the need for behavior-driven evaluation and optimizations when building interactive interfaces. This work can provide a starting point for newcomers in the field of interactive data systems.
TRANSFORMER: A Database-Driven Approach to Generating Forms for Constrained Interaction
Protiva Rahman, Arnab Nandi. ACM IUI 2019 (acceptance rate: 25%). [pdf][slides]
We present Transformer, a system that leverages the contents of the database to automatically optimize forms for constrained input settings. Our cost function models the user input effort based on the schema and data distribution. This is used by Transformer to find the user interface (UI) widget and layout with ideal input cost for each form field. We demonstrate through user studies that Transformer provides a significantly improved user experience, with up to 50% and 57% reduction in form completion time for smartphones and smartwatches respectively.
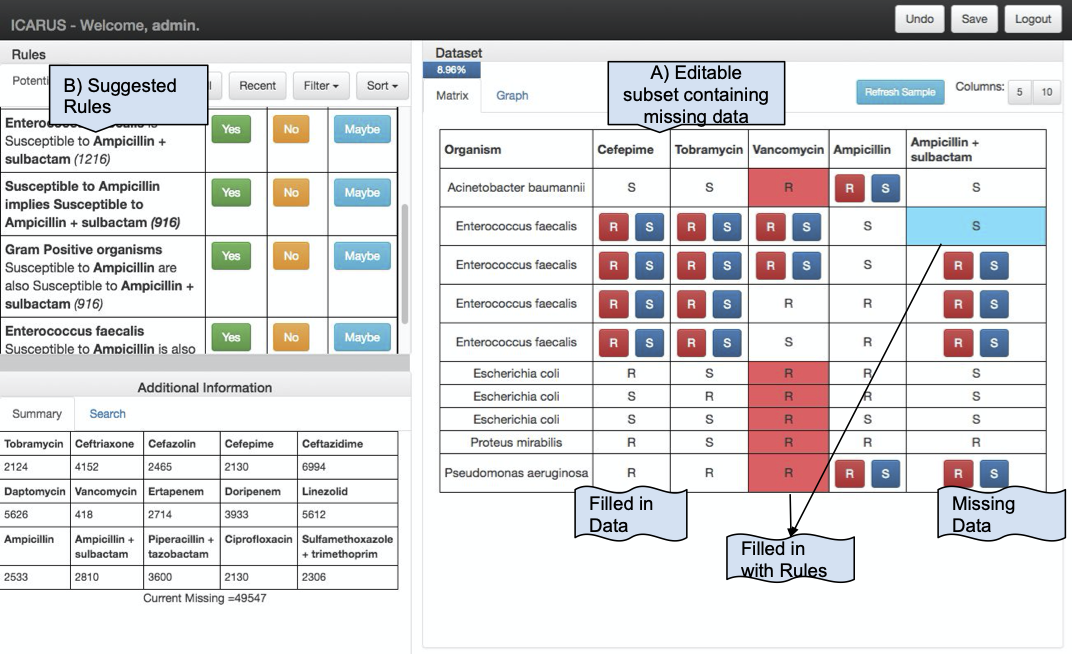
ICARUS: Minimizing Human Effort in Iterative Data Completion
Protiva Rahman, Courtney Hebert, Arnab Nandi. VLDB 2018 (acceptance rate: 17%). [pdf][website]
Icarus is an interactive data completion system that shows the user useful subsets for edits. It leverages the database structure to generalize the user's single edit to multiple cells through suggested rules, thereby reducing user effort and time. It is currently being used to complete multiple microbiology datasets at Ohio State's Biomedical Informatics department.
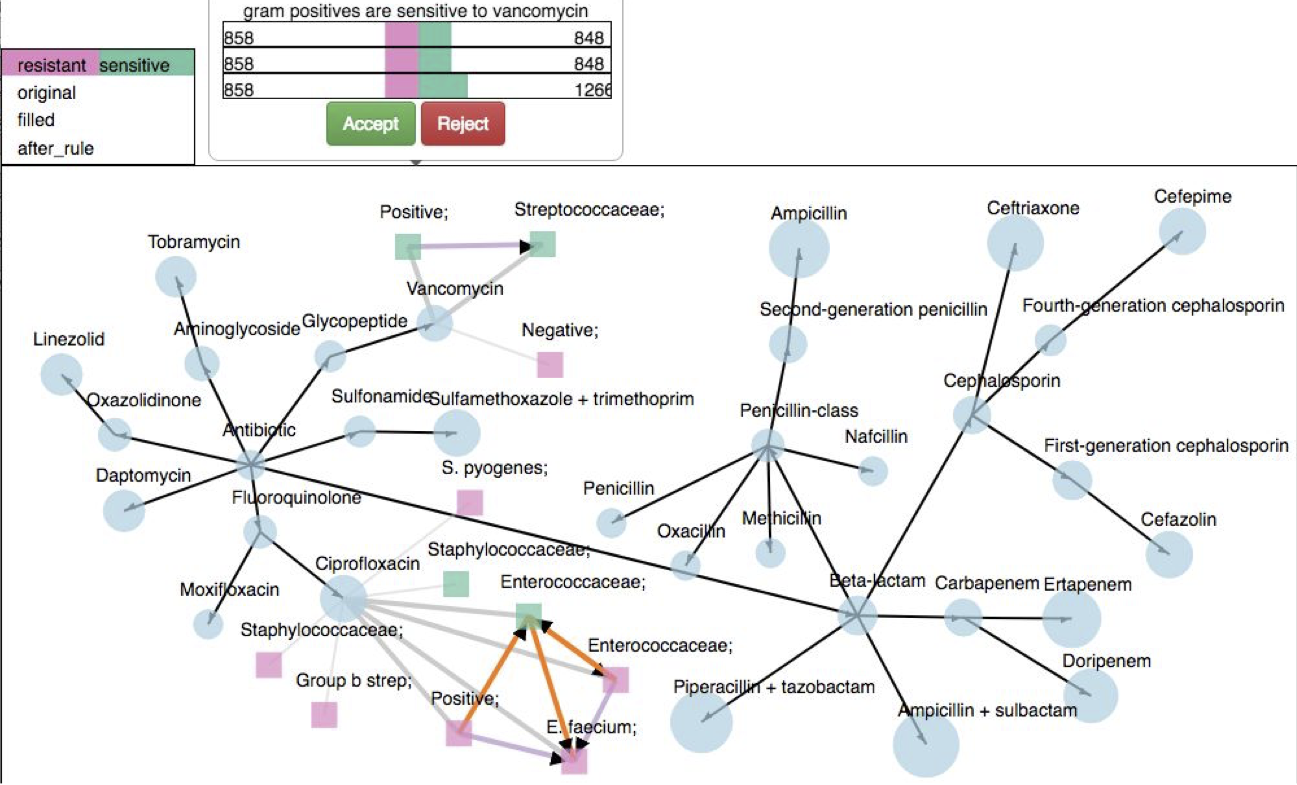
Exploratory Visualizations of Rules for Validation of Expert Decisions
Protiva Rahman, Jian Chen, Courtney Hebert, Preeti Pancholi, Mark Lustberg, Kurt Stevenson, Arnab Nandi. DSIA workshop at IEEE VIS 2018. [pdf][slides]
We present an interactive visualization system which allows users to explore relationships between rules, such as conflicts and redundancies, and see how applying the rule would affect the data. Our design allows users to interactively resolve conflicts by providing feedback on the correctness of each rule. Results of interacting with a rule are immediately applied to the data and redundant rules automatically removed.
Conference Presentations
- Protiva Rahman, Cheng Ye, Kate Mittendorf, Michele LeNoueNewton, Christine Micheel, Daniel Fabbri. Accelerated Data Curation of Colitis Cases. AMIA 2022. [pdf]
- Protiva Rahman, Daniel Fabbri. Automating Data from Unstructured Texts. AMIA 2021. [pdf]
- Protiva Rahman, Michele LeNoue-Newton, Sandip Chaugai, et al. Clinical and genomic predictors of brain metastases (BM) in non-small cell lung cancer (NSCLC): An AACR Project GENIE analysis. ASCO 2021. [pdf] [Oncology Nurse Advisor Article]
- Protiva Rahman, Erinn Hade, Emily Patterson, Courtney Hebert. Amplifying Domain Expertise in Antimicrobial Data Pipeline. AMIA Podium Abstract 2020. [pdf]
- Protiva Rahman, Elisabeth Root, Susan D. Moffatt-Bruce, Courtney Hebert. Designing an Interface for a Hospital Geographic Information System. AMIA 2020. [pdf]
- Protiva Rahman, Erinn Hade, Courtney Dewart et al. Predicting Empiric Antibiotic Coverage based on Patient Factors. AMIA 2019. [pdf]
- Protiva Rahman, Erinn Hade, Arnab Nandi et al. Derivation of Expert Consensus Rules for Missing Antimicrobial Susceptibility Data. AMIA 2018. [pdf]
- Protiva Rahman, Courtney Hebert, Arnab Nandi. Enabling Effective Data Interaction for Domain Experts. IEEE International Conference on Healthcare Informatics (ICHI) PhD Symposium 2018. [pdf][slides][poster]
- Protiva Rahman, Courtney Hebert, Albert Lai. Parsing Complex Microbiology Data for Secondary Use. AMIA 2016. [pdf]